
티스토리 뷰
[MSA] Spring + STOMP + Kafka + Kubernetes + MongoDB 고가용성 이벤트 기반 그룹채팅 아키텍처
wans10 2023. 8. 14. 21:07이번에는 MSA(Micro-Service Architecture)를 구성하는데 있어 하나의 서비스에 해당하는 채팅기능을 개발해봅니다.
가용성을 위해 서버를 여러대로 확장하는 Scale-Out 을 하고 다양한 기술들을 활용해 볼텐데 사용될 기술의 사용 목적을 간단히 설명하고 시작하겠습니다.
- 구독/발행 기반의 STOMP 채팅
- MessageBroker로 Kafka
- 채팅내역을 저장하기 위한 MongoDB
- 여러대의 서버관리, 트래픽 분산처리와 장애복구를 위한 Kubernetes
Kafka와 MongoDB는 kubernetes 내부가 아닌 외부IP 에서 사용한다고 가정합니다.
대략적인 구조

데이터 처리 과정
- 사용자가 Stomp 커넥션을 요청
- Kubernetes LoadBalancing으로 여러대의 서버중 하나와 연결이 맺어짐
- 연결이 맺어진 사용자가 Kafka에 메세지를 발행하면
- 해당 메세지를 MongoDB에 저장하고
- Kafka 를 통해 구동중인 모든 서버에 있는 해당 구독자들에게 메세지를 보냄
STOMP 설정
이전에 다룬 적이 있어 간략하게 코드만 보겠습니다.
2023.07.01 - [Spring/채팅앱] - [Spring+Stomp] Stomp를 활용한 웹소켓 구현
[Spring+Stomp] Stomp를 활용한 웹소켓 구현
채팅에 핵심이라 볼 수 있는 실시간 채팅을 구현해 보겠습니다. 지난번에 게시판을 만들면서 웹소켓으로 채팅을 만들어본적이 있습니다. https://wans1027.tistory.com/19 [Spring] 게시판 API (10) 웹소켓을
wans1027.tistory.com
@Configuration
@EnableWebSocketMessageBroker
@RequiredArgsConstructor
public class StompConfig implements WebSocketMessageBrokerConfigurer {
private final StompHandler stompHandler;
@Override
public void registerStompEndpoints(StompEndpointRegistry registry) {
registry.addEndpoint("/ws/chat").setAllowedOriginPatterns("*").withSockJS();
}
@Override
public void configureMessageBroker(MessageBrokerRegistry registry) {
//registry.enableSimpleBroker("/topic");
// 메세지 발행 요청 url -> 메세지 보낼 때
registry.setApplicationDestinationPrefixes("/app");
}
@Override
public void configureClientInboundChannel(ChannelRegistration registration) {
registration.interceptors(stompHandler);
}
}기본 설정입니다. 전과 다르게 registry.enableSimpleBroker를 사용하지 않고 Kafka를 사용해 이벤트 기반으로 동작하게 할 것이기 때문에 주석처리 해주었습니다.
@RequiredArgsConstructor
@Component
@Slf4j
public class StompHandler implements ChannelInterceptor {
@Override
public Message<?> preSend(Message<?> message, MessageChannel channel) {
//log.info("Stomp Handler 실행");
StompHeaderAccessor headerAccessor = StompHeaderAccessor.wrap(message);
// 헤더 토큰 얻기
//String authorizationHeader = String.valueOf(headerAccessor.getNativeHeader("Authorization"));
return message;
}
@EventListener
public void handleWebSocketConnectionListener(SessionConnectedEvent event){
log.info("사용자 입장");
}
@EventListener
public void handleWebSocketDisconnectionListener(SessionDisconnectEvent event){
log.info("사용자 퇴장");
}
}StompHandler를 이용해 JWT등 보안인증처리 또한 할 수 있습니다.
@RequiredArgsConstructor
@RestController
@Slf4j
public class MessageController {
private final KafkaMessageService kafkaMessageService;
@MessageMapping("/message")
public void sendMessage(MessageDto message) throws ExecutionException, InterruptedException {
//메세지 서비스 로직
}
}컨트롤러입니다. 내부에 메세지가 들어오면 수행할 서비스 로직을 넣어주면 됩니다.
메세지를 발행할때 Destination을 /app/message 로 설정하면 됩니다.
Kafka
kafka는 이벤트 브로커입니다.
이벤트 브로커는 메시지 브로커가 될 수 있습니다. 하지만 그 반대는 불가능 합니다.
이전에 RabbitMQ를 메시지 브로커로 사용해봄으로써 메시지 브로커에 기본적인 이해를 해보았습니다.
이후 진행될 내용을 쉽게 이해하기 위해서 한번 보시는걸 추천드립니다.
2023.07.29 - [Spring/채팅앱] - [Spring 채팅앱 성능 개선기 6] 외부 MessageBroker (RabbitMQ) 적용
[Spring 채팅앱 성능 개선기 6] 외부 MessageBroker (RabbitMQ) 적용
이전 포스트 2023.07.25 - [Spring/채팅앱] - [Spring 채팅앱 성능 개선기 5] Spring Cloud LoadBalancing 적용 [Spring 채팅앱 성능 개선기 5] Spring Cloud LoadBalancing 적용 이전게시글 2023.07.13 - [Spring/채팅앱] - [Spring 채
wans1027.tistory.com
Kafka를 사용하는 이유
- 클러스터링을 통한 고가용성, 확장성, 안전성 확보
카프카에서 리플리케이션(replication) 이란 각 메세지들을 여러 개로 복제해서 카프카 클러스터내 브로커들에 분산시키는 동작을 의미 합니다.
이러한 리플리케이션 동작 덕분에 하나의 브로커가 종료 되더라도 카프카는 안정성을 유지 할 수 있습니다.
메세지가 처리되면 삭제되는 RabbitMQ와 다르게 Kafka는 처리가 되어도 기록이 남아있습니다.
- MSA 느슨한 결합
마이크로 서비스간 결합도를 낮춰 하나의 서비스에 응집도를 높일 수 있습니다.
지금은 메시지 브로커로 채팅 서비스 내에서만 동작하도록 하지만 나중에 개발할 다른 마이크로 서비스에 이벤트 브로커로 kafka Topic을 분리하여 느슨한 결합을 통해 개발 가능합니다.
Kafka 구성요소
• 주키퍼(Zookeeper): 아파치 프로젝트 애플리케이션으로 카프카의 메타데이터(metadata) 관리 및 브로커의 정상상태 점검(health check) 을 담당 합니다.
• 카프카(Kafka) 또는 카프카 클러스터(Kafka cluster) : 아파치 프로젝트 애플리케이션으로 여러대의 브로커를 구성한 클러스터를 의미 합니다.
• 브로커(broker) : 카프카 애플리케이션이 설치된 서버 또는 노드를 의미 합니다.
• 프로듀서(producer): 카프카로 메세지를 보내는 역할을 하는 클라이언트로 총칭 합니다.
• 컨슈머(consumer) : 카프카에서 메세지를 꺼내가는 역할을 하는 클라이언트를 총칭 합니다.
• 토픽(topic) : 카프카는 메시지 피드들을 토픽으로 구분하고, 각 토픽의 이름은 카프카 내에서 고유 합니다.
• 파티션(partition) : 병렬 처리 및 고성능을 얻기 위해 하나의 토픽을 여러개로 나눈 것을 의미 합니다
• 컨슈머그룹(consumer group) : 컨슈머들이 모인 하나의 집단입니다.
Kafka의 기본적인 내용과 사용이유에 대해 알아보았습니다.
이제 Kafka를 사용해 서버 여러대를 사용할때 발생하는 문제점을 해결해 보고 코드를 보도록 하겠습니다.
문제점
다수로 구성된 채팅 서버에서 STOMP를 이용함으로써 WebSocket Conncetion Session이 각 서버마다 다르게 연결되어 있습니다. 여기서 말하는 Session은 웹의 쿠키세션과 다른 Websocket Session입니다.
2023.07.29 - [Spring/채팅앱] - [Spring 채팅앱 성능 개선기 6] 외부 MessageBroker (RabbitMQ) 적용
이전의 문제와 동일한 문제입니다. RabbitMQ를 사용해 해결했었는데 Kafka를 사용하면 어떤방법으로 사용하고 해결해야 할지 최대한 서버에 부하가 적은 방법으로 해결방법을 찾고 이해해봅시다.

그림에서 사용자들은 서버와 연결을 맺고 있습니다.
사용자 1은 roomid1에 대해서 구독자이자 발행자이고 Connection Session은 Server1 입니다.
사용자 1이 발행한다면 roomid1을 구독중인 모든 구독자들이 메시지를 받아야 하지만 Server1과 Server2는 분리되어 있기에 사용자3은 메시지를 받지 못합니다.
해결방법은 두개의 서버를 연결할 통로를 Kafka로 만들면 됩니다.

Kafka로 어떻게 ?
Kafka 는 이벤트 기반입니다.
메시지브로커RabbitMQ에서는 세션마다 브로커 내부에서 Queue가 생성되었지만, Kafka는 단지 <메세지가 발행됨> 이라는 이벤트를 발생시키기만 하면 됩니다.
그림에서 Server1, Server2는 모두 kafka를 Listening중입니다.
사용자 1이 메시지를 send하면 Server1에서 kafka에 메세지 객체와 함께 발행 이벤트를 발생시킵니다.
Listening 하던 Server1과 Server2는 이벤트발생 사실을 알아차리고 넘어온 메세지 객체를 해석해 연결된 구독자들에게 전달합니다.
여기서 kafka의 장점인 느슨한 결합을 엿볼수 있습니다.
Server1은 단지 <메세지가 발행됨> 이라는 이벤트만 알렸습니다. 메세지가 발행되었으니 어떤거는 저장하고, 어떤거는 전송하고, 어떤거는 해석해라! 라는 명령을 내리지 않았습니다.
더 구체적으로 알아봅시다.
kafka의 partition, consumer, consumer group에 대해 알아야 할 필요가 있습니다.
아래 링크에 설명이 굉장히 잘되어있으니 보고 오시기 바랍니다.
https://www.popit.kr/kafka-consumer-group/
Kafka 운영자가 말하는 Kafka Consumer Group | Popit
이번에는 Consumer Group이라는 주제를 가지고 설명하려고 합니다. 이 내용 역시 제가 처음 카프카를 접했을때, 정말 이해가 안되고 어려웠던 부분이었습니다. 컨슈머 그룹에 대해 국내 자료들을 검
www.popit.kr
지금 서비스에서 하고 싶은건 Chat토픽의 파티션에 들어오는 데이터를 모든 서버가 Listening해야 한다는 것입니다.
그러기 위해선 각 서버마다 다른 Consumer Group ID를 가져야 합니다.
아래그림과 같은 구조로 설계할 것입니다.
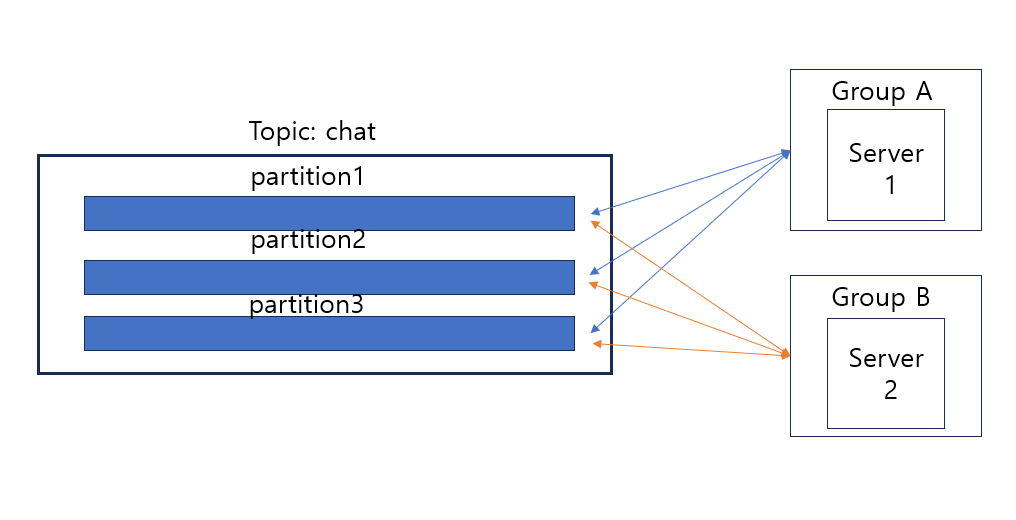
이런 구조면 트래픽 분산처리가 아니지 않나?
생각해보면 대부분의 부하를 일으키는 원인은 세션을 연결하기위한 HandShake과정과, 보안처리, 메시지를 DB에 저장하는 로직에서 발생합니다. 이것들만 로드밸런싱을 통해 분산하면 됩니다.
메세지를 구독자에게 전달하는 과정은 세션하나하나 전달하는게 아닌 발행/구독 구조이기 때문에 모든 서버가 동시에 실행해도 큰 부하를 차지하지 않습니다.
설명은 끝났습니다. 코드로 보겠습니다.
구성설정이 매우쉬웠던 RabbitMQ와 다르게 Kafka는 Spring에서의 구성설정이 조금 복잡해 보일 수 있습니다.
Kafka를 로컬로 설치하든 도커로 설치하든 상관없습니다.
도커를 사용한다면 설치시 docker-compose.yaml
public class KafkaConstants {
private static String name = UUID.randomUUID().toString();
public static final String KAFKA_TOPIC = "test-chat";
public static final String GROUP_ID = name;
public static final String KAFKA_BROKER = "localhost:9092";
public static List<Integer> partitionList;
}kafka기본설정에 필요한 요소들입니다. GROUP_ID를 랜덤으로 설정해 같은 이미지의 서비스 배포시 ID가 다르게끔 설정합니다.
@EnableKafka
@Configuration
@Slf4j
public class KafkaConsumerConfig {
@Bean
public ConcurrentKafkaListenerContainerFactory<String, ResponseMessageDto> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, ResponseMessageDto> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
ContainerProperties prop = factory.getContainerProperties();
prop.setConsumerRebalanceListener(rebalanceListener());
return factory;
}
@Bean
public ConsumerFactory<String, ResponseMessageDto> consumerFactory() {
JsonDeserializer<ResponseMessageDto> deserializer = new JsonDeserializer<>(ResponseMessageDto.class);
deserializer.setRemoveTypeHeaders(false);
deserializer.addTrustedPackages("*");
deserializer.setUseTypeMapperForKey(true);
ImmutableMap<String, Object> config = ImmutableMap.<String, Object>builder()
.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaConstants.KAFKA_BROKER)
.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class)
.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, deserializer)
.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
.put("group.id", KafkaConstants.GROUP_ID)
.build();
return new DefaultKafkaConsumerFactory<>(config, new StringDeserializer(), deserializer);
}
@Bean
public ConsumerAwareRebalanceListener rebalanceListener() {
return new ConsumerAwareRebalanceListener() {
@Override
public void onPartitionsAssigned(Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
// here partitions
List<Integer> partList = new ArrayList<>();
for (TopicPartition partition : partitions) {
int partition1 = partition.partition();
partList.add(partition1);
log.info("사용중인파티션:{}", partition1);
}
KafkaConstants.partitionList = partList;
}
};
}
}@Configuration
@EnableKafka
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, ResponseMessageDto> producerFactory() {
return new DefaultKafkaProducerFactory<>(kafkaProducerConfiguration());
}
@Bean
public Map<String, Object> kafkaProducerConfiguration() {
return ImmutableMap.<String, Object>builder()
.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaConstants.KAFKA_BROKER)
.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class)
.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class)
.put("group.id", KafkaConstants.GROUP_ID)
.build();
}
@Bean
public KafkaTemplate<String, ResponseMessageDto> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
Kafka Consumer와 Producer에 대한 설정입니다. kafka 를 연결하고 Message객체 Template을 구성합니다.
@Service
@RequiredArgsConstructor
@Slf4j
public class KafkaMessageService {
private final KafkaTemplate<String, ResponseMessageDto> kafkaTemplate;
private final MessageService messageService;
//producer
public void send(String topic, MessageDto messageDto) {
log.info("send Message : " + messageDto.getDetailMessage());
try{
ResponseMessageDto responseMessageDto = messageService.SaveAndChangeToMessageResponseDto(messageDto);
kafkaTemplate.send(topic,responseMessageDto);
}catch (Exception e){
e.printStackTrace();
throw new RestException(HttpStatus.NOT_ACCEPTABLE,"SAVE Failed");
}
}
//consumer
private final SimpMessageSendingOperations sendingOperations;
private final SimpMessagingTemplate template;
@KafkaListener(topics = KafkaConstants.KAFKA_TOPIC)
public void consume(ResponseMessageDto responseMessageDto) throws IOException {
template.convertAndSend("/topic/"+responseMessageDto.getRoomId(),responseMessageDto);
}
}Controller에서 메세지가 들어오면 kafka에 send()되는데 그 전에, 사용자가 보내는 메세지에는 보낸시간이 담겨져 있지 않습니다. 서버에서 메시지를 받아 DB에 저장할 때의 시간을 등록하고 ResponseDto로 변환해 send파라미터로 넘깁니다.
@KafkaListener로 카프카 이벤트를 받을 수 있습니다.
받으면 메시지의 roomId를 Key로 구독자들에게 전송합니다.
MongoDB
채팅 내역을 저장하는데는 MongoDB를 사용합니다.
MongoDB는 고성능, 고가용성 및 쉬운 확장성을 제공하는 NoSQL, Document 지향 데이터베이스입니다.
Read/Write가 빠르다는게 특징으로 수정이 일어나지 않는 채팅 특성과 맞습니다.단점으로는 OS의 메모리를 사용하기 때문에 용량이 너무 커지면 문제가 됩니다. Batch를 통해 주기적으로 오래된 채팅은 삭제해야 합니다.
MongoDB에 대한 SpringBoot 설정에 대한 코드는 찾아보면 많으니 생략하겠습니다.
Kubernetes LoadBalancing
제대로 설명하려면 끝없이 길어지고 저도 공부중이라 깊게까진 몰라서 과정정도만 보겠습니다.
LoadBalancing을 간단히 설명하자면 하나의 IP와 PORT를 가지고 여러대의 서버를 정해진 규칙으로 실행할 수 있게 해줍니다.
예를 들어 같은 채팅서버가 포트만 다르게 3개 구동 중 입니다.{ localhost:8080, localhost:8888, localhost:8765}
이 3개를 싸잡아 localhost:8084 로 퉁칠수 있습니다. 8084를 호출하면 3개의 서버중 한대가 응답합니다.
전에 Spring Cloud LoadBalancing, Gateway, Eureka를 사용해 로드밸런싱을 구현해 보았습니다.
2023.07.25 - [Spring/채팅앱] - [Spring 채팅앱 성능 개선기 5] Spring Cloud LoadBalancing 적용
2023.07.31 - [Spring/채팅앱] - [Spring Gateway+Eureka] Spring Cloud Gateway + ServiceDiscovery(Eureka)
Spring Cloud를 사용하면 단점이 있었습니다.
서비스 서버, LoadBalancing서버, ServiceDiscovery를 일일히 가동해야 했고 AWS EC2같은 인스턴스로 모두 등록한다고 하면 생각만 해도 귀찮습니다.
그래서 이번에는 Kubernetes를 통해 위에서 만든 채팅서비스를 배포하고 LoadBalancing을 구현, 후에 개발할 다른 마이크로서비스까지 한번에 관리할 수 있게 해보겠습니다.
<<참고로 Kubernetes는 "k8s"라고도 하는데 그 이유는 k와s 사이에 8문자가 들어가서 그렇다고 합니다.>>
먼저 만든 서비스를 .jar로 만들고 DockerHub에 올리기 위해 Image화 해야합니다.
DockerHub에 springboot 이미지 push 하는 방법은 검색하면 많이 나오니 생략하겠습니다.
저는 쿠버네티스 환경을 Vagrant와 VirtualBox를 통해 로컬에서 진행했습니다.
Amazon, microsoft, Google등에서 제공하는 kubernetes Cloud를 통해 하면 더 쉽게 가능합니다.

마스터노드 1개 워커노드 2개로 클러스터를 구성했습니다.
쿠버네티스에 서버를 복제하고 로드밸런싱까지 한번에 해주는 .yaml 파일을 작성합니다.
명령어가 입력되어있는 yaml 파일로 긴 명령어 없이 이 파일만 실행하면 됩니다.
apiVersion: v1
#List로 설정하여 하나의 yaml 파일 안에 설정할 수 있다.
kind: List
items:
- apiVersion: v1
kind: Service
metadata:
name: chat-load-svc
spec:
type: LoadBalancer
selector:
app: chatservice-app
ports:
- protocol: TCP
port: 8080 #외부노출포트
targetPort: 80
nodePort: 32000
- apiVersion: apps/v1
kind: Deployment
metadata:
name: chatservice-app
spec:
replicas: 2 #채팅서버 두개 구동
minReadySeconds: 5
selector:
matchLabels:
app: chatservice-app
template:
metadata:
name: chatservice-app-pod
labels:
app: chatservice-app
spec:
containers:
- name: chatservice-app
image: 도커허브에올린 레포지토리
imagePullPolicy: Always
ports:
- containerPort: 80
해당 yaml파일을 명령어를 통해 실행시키면
kubectl apply -f chatservice.yaml2개의 동일한 서버가 구동되었고

로드밸런서를 통해 하나의 IP와 포트가 쿠버네티스 서비스를 통해 노출되었습니다.

확인
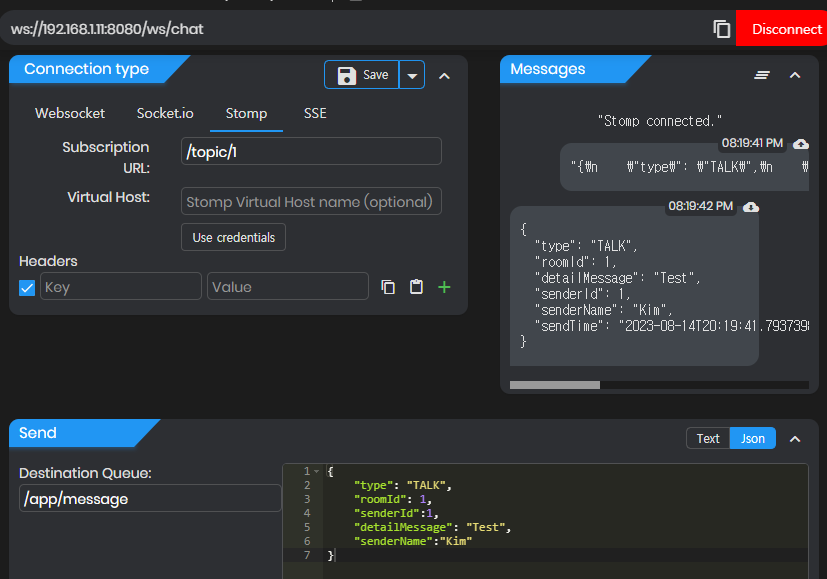
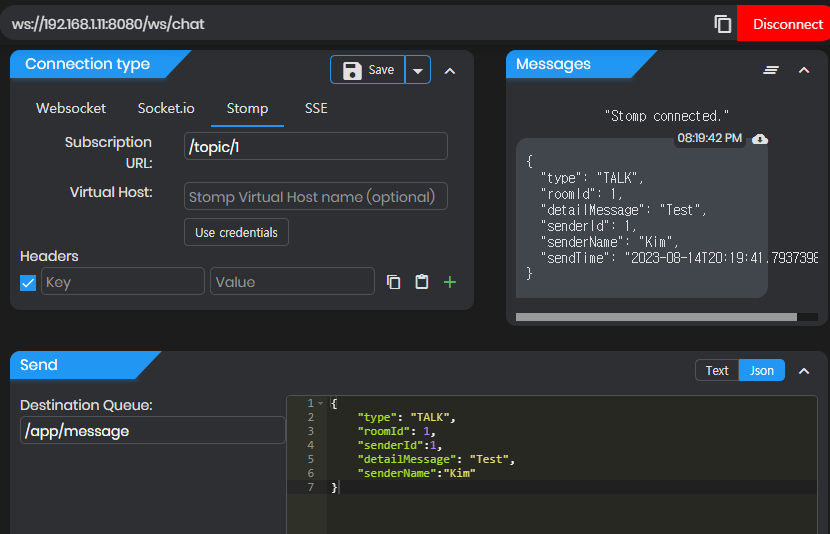
연결과 메세지 보내기, 저장까지 성공입니다.
두 웹소켓은 같은 IP와 포트로 연결했지만 로그를 통해 보면 두개의 서버가 각각 동작중입니다.

마치며
고가용성을 위한 채팅서버 클러스터링 개발 과정을 기록해보았습니다.
최대한 이해하기 쉽게 적어보려 했는데 좀 난잡해진 느낌이 있네요.
Kafka의 사용법과 원리 공부를 위해 메시지 브로커로 사용했을 뿐, Kafka는 RabbitMQ와 비교해 라우팅기능이 없기때문에 채팅기능만을 고려한 Broker를 선택해 본다면 RabbitMQ를 선택하는게 맞는 것 같습니다.
- Total
- Today
- Yesterday
- 푸시알림동작원리
- FCM
- Flutter
- Spring WebSocket
- Spring 채팅
- MessageBroker
- bcrypt
- 게시판 채팅
- ChattingApp
- Spring Stomp
- Vmmem종료
- Cache
- springboot
- 로컬캐시
- Spring
- Kubernetes
- Stomp Kafka
- ERD설계
- Security
- authorization
- Stomp RabbitMQ
- Spring RabbitMQ
- Vmmem
- spring orphan
- Authentication
- 웹소켓 채팅
- Bcypt
- Spring 대댓글
- nativeQuery
- loadbalancing
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |